Parallel FFT (CUDA / OpenMPI)
Oct 26, 2023
·
1 min read
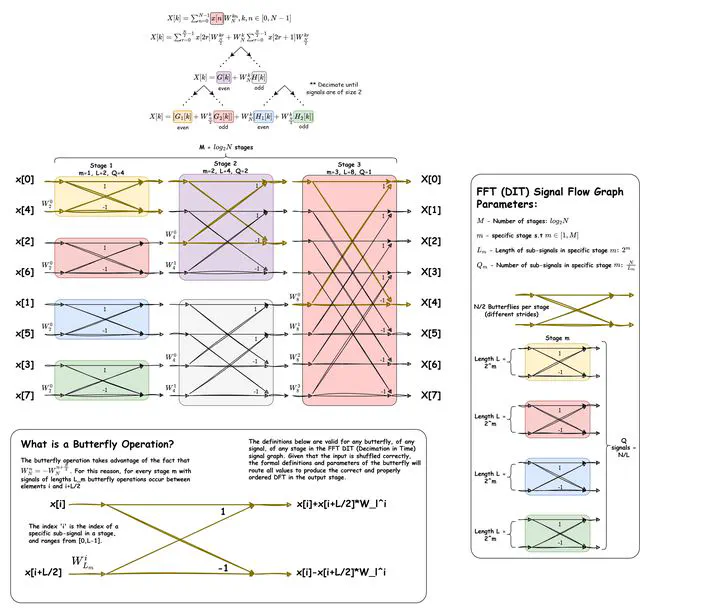
This project implements parallel and accelerated FFT variants in OpenMPI and CUDA, grounded in the mathematical and algorithmic foundations of the FFT and its historical development. It highlights the divide-and-conquer structure that reduces DFT complexity from O(N^2) to O(N log N), then develops the additional theory needed for parallel execution and addresses key optimization issues. Results are presented along with a discussion of known issues and potential improvements. See the presentation below for the technical walkthrough, and download the report for the full methodology and analysis.
Project presentation (PDF).