DeepSeek mHC
Slides for my DeepSeek mHC presentation, covering the key ideas and architecture choices along with where the approach fits in modern transformer pipelines.
Presentation (PDF): mHC.pdf
I’m a hardware engineer at AMD (Vancouver) working at the intersection of computer architecture, RTL design, performance modeling, and HW/SW co-design. My work focuses on high-performance I/O subsystems, memory-system behavior, coherent and non-coherent interconnects, DMA/RDMA, PCIe, NoC, and low-power design, with an emphasis on building and analyzing performance-critical hardware. I also work on custom in-house performance simulation and architecture analysis to study bottlenecks, reason about throughput and latency, and correlate model behavior with implementation details.
I earned a BASc in Computer Engineering from UBC (2024). My broader technical interests center on accelerators, ML systems, attention/transformer workloads, and the hardware/software tradeoffs that drive real end-to-end throughput.
BASc Computer Engineering
University of British Columbia (2024)
I’m interested in performance-critical systems for modern ML—especially attention and sequence models—where algorithmic choices show up directly in memory traffic, kernel design, and end-to-end latency. I like working at the boundary between architecture and software: profiling bottlenecks, forming clear hypotheses about where time/data is going, and turning that into measurable speedups.
More broadly, I’m drawn to computer architecture (memory systems, interconnects, accelerators, HW/SW tradeoffs) and to the mathematical foundations that make good engineering decisions possible (probability/statistics, linear algebra, signal processing).
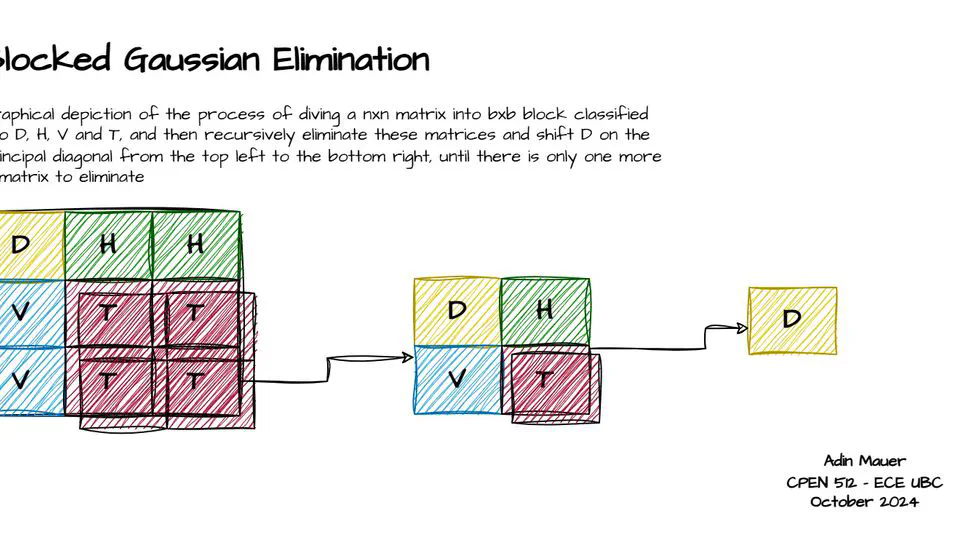
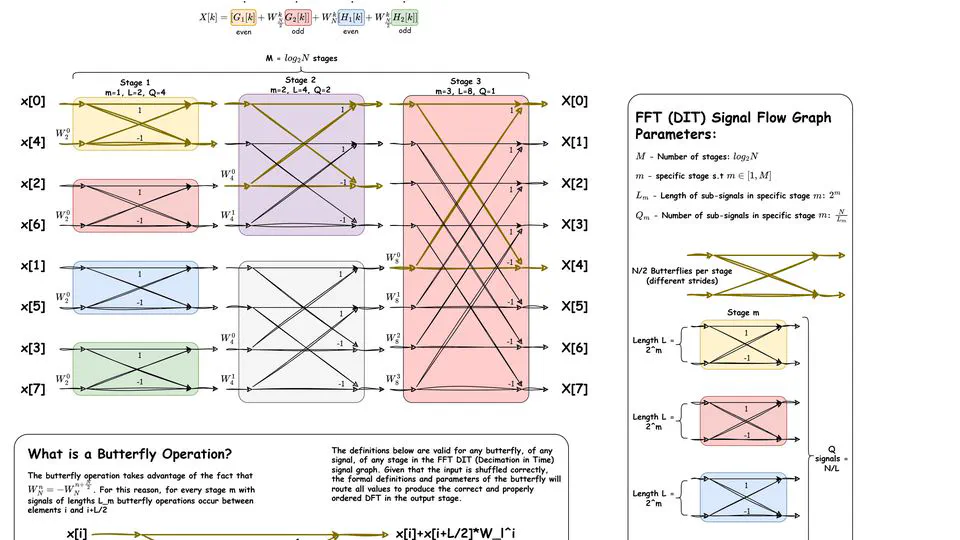
I keep the theory grounded through hands-on accelerated computing work. For example, in my final semester at UBC I took CPEN 512 (Parallel and Configurable Computer Architecture), where I implemented dense linear algebra kernels (matmul, LU decomposition) across multiple parallel programming models (OpenMPI, pthreads, CUDA, Bluespec, Vectorblox). For the final project, I implemented a Cooley–Tukey FFT using CUDA and OpenMPI.
Slides for my DeepSeek mHC presentation, covering the key ideas and architecture choices along with where the approach fits in modern transformer pipelines.
Presentation (PDF): mHC.pdf
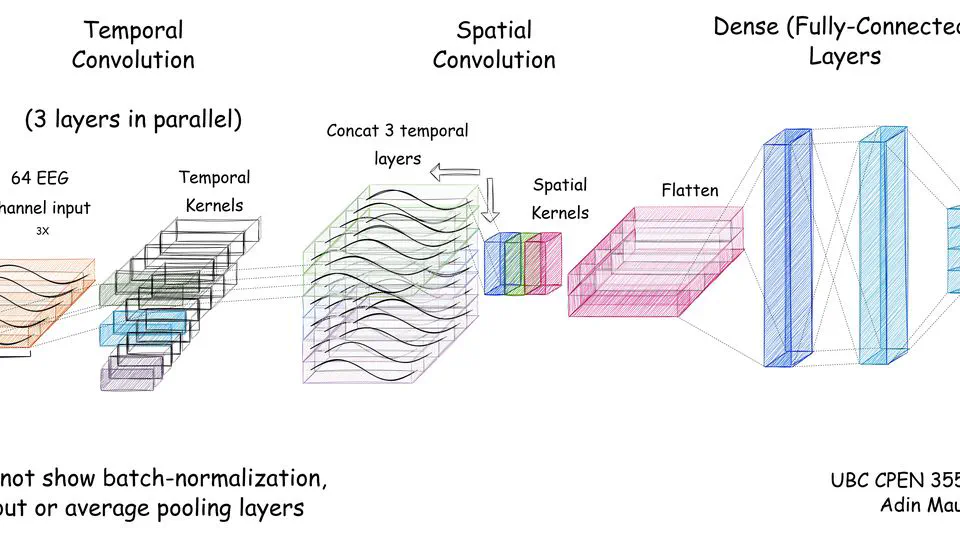
FlashAttention is an IO-aware attention algorithm designed to reduce memory traffic and improve throughput by fusing attention operations and recomputing intermediates as needed. This post outlines the key ideas, practical implications for large-sequence workloads, and where the approach fits in modern transformer pipelines. I presented this paper to the UBC CPEN 511 class in February 2025. See the presentation below for the walkthrough, and download the source document for the full technical details.
Source document (PDF): Review_FlashAttention_AdinMauer.pdf